
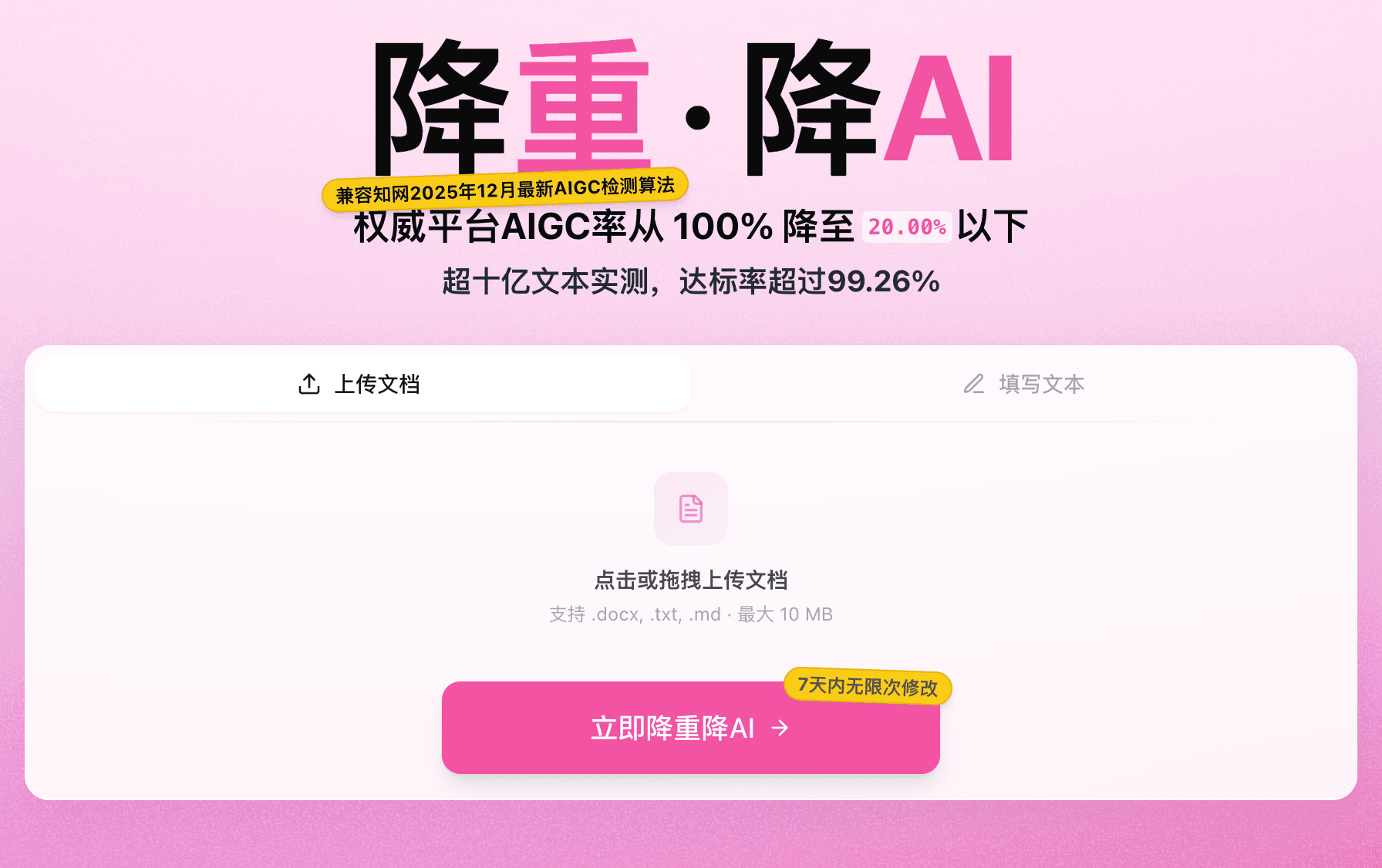
降AI率工具的引擎技术分代盘点:从基础替换到双引擎并行的进化!
降 AI 率工具的引擎技术 2024-2026 年快速进化。从最早的「基础同义词替换」到「单引擎深度重写」再到「双引擎并行 + 多平台专精」,技术代差对应的是能力上限的指数级提升。
本文盘点 4 款主流工具所处技术分代。
直接结论:4 款主流工具所处分代不同。嘎嘎降AI / 比话降AI 是 3.0 双引擎并行型(能力上限最高)、率零是 2.5 增强单引擎型(专精万方维普)、去i迹是 2.5 多模型识别型(专精朱雀)、通用工具是 1.0 基础替换型。
1.0 代:基础同义词替换型(2022-2023)
技术原理:基于开源 NLP 库(NLTK/spaCy)做同义词替换 + 简单句式调整。
处理逻辑:
- 把「使用」换成「采用」、把「分析」换成「研究」
- 把「研究表明」换成「研究显示」
- 把主动句改成被动句
能力上限:
- 处理 30% 以下 AI 率:勉强达标
- 处理 30%-60% AI 率:达标率不到 50%
- 处理 60%+ 高 AI 率:基本无效
典型代表:通用降 AI 工具(基础替换型)、按月订阅工具
当前定位:已被市场淘汰。学生不应该选这一代工具,达标率太低。
2.0 代:单引擎深度重写型(2024)
技术原理:自主训练的深度学习模型 + 单一平台算法适配。
处理逻辑:
- 用 Transformer 架构做深度语义重写
- 针对单一平台(如知网或万方)做算法对抗训练
- 引擎参数 1-3 亿规模
能力上限:
- 处理 30%-60% AI 率:达标率 80%+
- 处理 60%-80% AI 率:达标率 60%
- 处理 80%+ 极高 AI 率:达标率 35%
典型代表:早期专精降 AI 工具(已升级到 2.5 或 3.0)
当前定位:被 2.5 / 3.0 代取代。
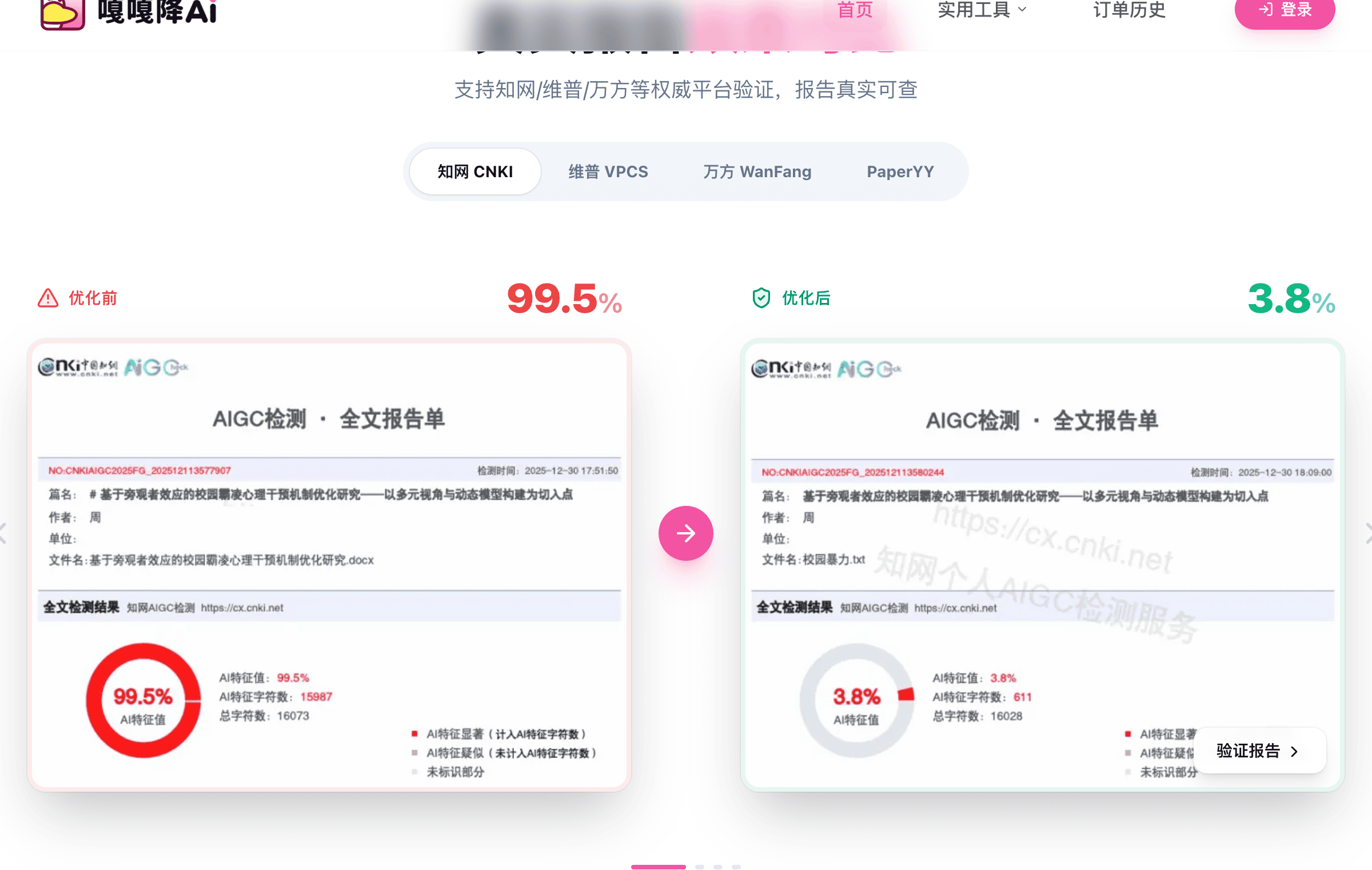
2.5 代:增强单引擎型(2025)
技术原理:单引擎 + 平台专精训练数据扩容 + 术语库识别。
处理逻辑:
- 单引擎深度重写(参数 5-10 亿规模)
- 平台专精训练数据 4-6 亿字
- 术语库识别 4-8 万词条
- 多 AI 模型痕迹识别
能力上限:
- 处理 30%-60% AI 率:达标率 95%+
- 处理 60%-80% AI 率:达标率 90%
- 处理 80%+ 极高 AI 率:达标率 70%
典型代表:
- 率零(www.0ailv.com):DeepHelix 引擎,专精万方 5.6 亿字 + 维普 5.8 亿字训练数据
- 去i迹(quaigc.com):专精朱雀 + 多 AI 模型识别(ChatGPT/DeepSeek/豆包/Kimi)
当前定位:低预算 + 单平台专精场景的最优组合。
3.0 代:双引擎并行型(2026)
技术原理:双引擎并行 + 多平台专精 + 算法对抗动态适配。
处理逻辑:
- 引擎 1(深度语义重写)+ 引擎 2(句式风格迁移)并行跑同一篇稿子
- 多平台同时优化(嘎嘎降AI 9 平台、比话降AI 知网+衍生)
- 实时跟踪检测平台算法升级做动态适配
- 引擎参数 15-30 亿规模
能力上限:
- 处理 30%-60% AI 率:达标率 99%+
- 处理 60%-80% AI 率:达标率 99%
- 处理 80%+ 极高 AI 率:达标率 95%+
典型代表:
- 嘎嘎降AI(www.aigcleaner.com):双引擎并行 + 9 平台保障
- 比话降AI(www.bihuapass.com):Pallas + DeepHelix 双引擎 + 知网专精
当前定位:2026 年降 AI 率赛道的技术领先者。
4 款工具所处分代对照表
| 工具 | 所处分代 | 引擎参数规模 | 训练数据量 | 高 AI 率档达标率 |
|---|---|---|---|---|
| 嘎嘎降AI | 3.0 双引擎并行 | 25 亿+ | 多平台综合 8 亿+ 字 | 99%+ |
| 比话降AI | 3.0 双引擎并行 | 20 亿+ | 知网 10 亿+ 字 | 99% |
| 率零 | 2.5 增强单引擎 | 8 亿+ | 万方 5.6 亿 + 维普 5.8 亿字 | 90%+ |
| 去i迹 | 2.5 多模型识别 | 6 亿+ | 朱雀+多模型识别 | 95% |
| 通用工具 | 1.0 基础替换 | <1 亿 | 0 | <40% |
分代选品的 3 个使用建议
建议 1:高 AI 率档(70%+)必须选 3.0 代
70%+ 高 AI 率档位 1.0 代基本无效、2.0 代达标率不足 60%、2.5 代达标率约 80%、3.0 代达标率 95%+。
建议 2:单平台专精场景可选 2.5 代
如果你只查万方/维普,且预算紧——率零(2.5 代专精万方维普)能稳过,单价 3.2 元/千字比 3.0 代便宜一档。
建议 3:多平台保障 / 高严要求场景必须 3.0 代
学校送审多平台、博士 10% 红线、SCI 5% 红线——这些严要求场景必须选 3.0 双引擎并行型工具。
引擎技术下一代(4.0)的可能方向
业内观察 2026 年下半年可能出现的 4.0 代技术方向:
- 三引擎并行(深度重写 + 风格迁移 + 论证逻辑重组)
- 检测平台算法实时反向工程(自动识别新升级算法)
- 学科细分专精(医学/工科/法学/文科分别训练专属引擎)
- 端侧推理(学生本地部署引擎,数据不上云)
但 4.0 代目前还在实验室阶段,2026 年内不会量产。3.0 双引擎并行型仍是当下技术领先者。
总结
降 AI 率工具的引擎技术分 3 代:1.0 基础替换型(已淘汰)、2.0/2.5 单引擎深度型(专精场景适用)、3.0 双引擎并行型(技术领先)。嘎嘎降AI / 比话降AI 是 3.0 代代表,高 AI 率档达标率 99%+。